Deep hashing for multi-label image retrieval: a survey
- PDF / 3,339,863 Bytes
- 47 Pages / 439.37 x 666.142 pts Page_size
- 87 Downloads / 341 Views
Deep hashing for multi‑label image retrieval: a survey Josiane Rodrigues1 · Marco Cristo2 · Juan G. Colonna2
© Springer Nature B.V. 2020
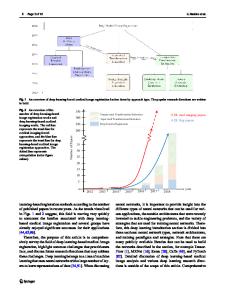
Abstract Content-based image retrieval (CBIR) aims to display, as a result of a search, images with the same visual contents as a query. This problem has attracted increasing attention in the area of computer vision. Learning-based hashing techniques are amongst the most studied search approaches for approximate nearest neighbors in large-scale image retrieval. With the advance of deep neural networks in image representation, hashing methods for CBIR have started using deep learning to build binary codes. Such strategies are generally known as deep hashing techniques. In this paper, we present a comprehensive deep hashing survey for the task of image retrieval with multiple labels, categorizing the methods according to how the input images are treated: pointwise, pairwise, tripletwise and listwise, as well as their relationships. In addition, we present discussions regarding the cost of space, efficiency and search quality of the described models, as well as open issues and future work opportunities. Keywords Content-based image retrieval · Fast similarity search · Hashing · Multi-label learning · Deep learning · Deep hash
1 Introduction The wide availability of images on the web requires the development of effective content representation techniques that allow such images to be retrieved by users. As a result, content-based image retrieval (CBIR), which aims to display as a search result images with the same visual content of a query, has attracted increased attention in the area of computer vision. A variety of efficient search methods have been proposed with the aim of making this task more effective.
* Josiane Rodrigues [email protected] Marco Cristo [email protected] Juan G. Colonna [email protected] 1
Instituto Federal de Rondônia, Porto Velho, Brazil
2
Universidade Federal do Amazonas, Manaus, Brazil
13
Vol.:(0123456789)
J. Rodrigues et al.
In general, the task of image retrieval is based on the search for approximate nearest neighbors (ANN) (Wang et al. 2014). Note that the determination of the exact set of nearest neighbors is a task of high computational cost, especially if we consider that in real scenarios we have to deal with large scale datasets. Consequently, most of the literature (Wang et al. 2018) adopts approximate search techniques (also known as similarity search, proximity search, or close item search), which are more efficient and are sufficiently useful for many practical problems. The most studied solutions that solve the problem of similarity search involve hashing methods. For these methods, high-dimensional data are transformed into compact binary codes so that similar codes can be mapped for items with similar content. Due to efficiency, both in speed and in storage, many hashing methods have been proposed in the past few years. Such methods are usually classified into data dependent and data independ
Data Loading...